Distributed Deep Learning
Training Framework
Train complex deep learning models across heterogeneous consumer-grade PCs connected via the internet. Ravnest combines data and model parallelism with a novel asynchronous training approach.
Architecture
How It Works
Ravnest orchestrates distributed training through a four-stage pipeline that handles cluster formation, parallel training, global synchronization, and fault recovery.
Matchmaking & Cluster Formation
Requester and compute nodes connect to an intermediary matchmaking server that profiles each node's hardware capabilities and network characteristics. Nodes are algorithmically grouped into clusters with similar data transfer rates and compute power, minimizing intra-cluster communication overhead. The model is then fragmented into submodels distributed across the cluster.
Zero-Bubble Asynchronous Model Parallel Training
Within each cluster, the model is partitioned across nodes using model parallelism. A zero-bubble pipeline schedule feeds micro-batches through the pipeline stages asynchronously, ensuring no node sits idle waiting for forward or backward passes from adjacent stages. This eliminates the pipeline bubble problem that plagues synchronous pipeline parallelism.
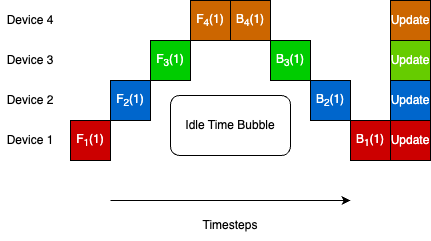

Parallel Multi-Ring All-Reduce
After local training iterations within clusters, global parameter averaging is performed using a parallel multi-ring all-reduce algorithm. This distributes the communication load evenly across all nodes, avoiding the bottleneck of a centralized parameter server. Synchronization is triggered periodically rather than after every iteration, amortizing communication cost.
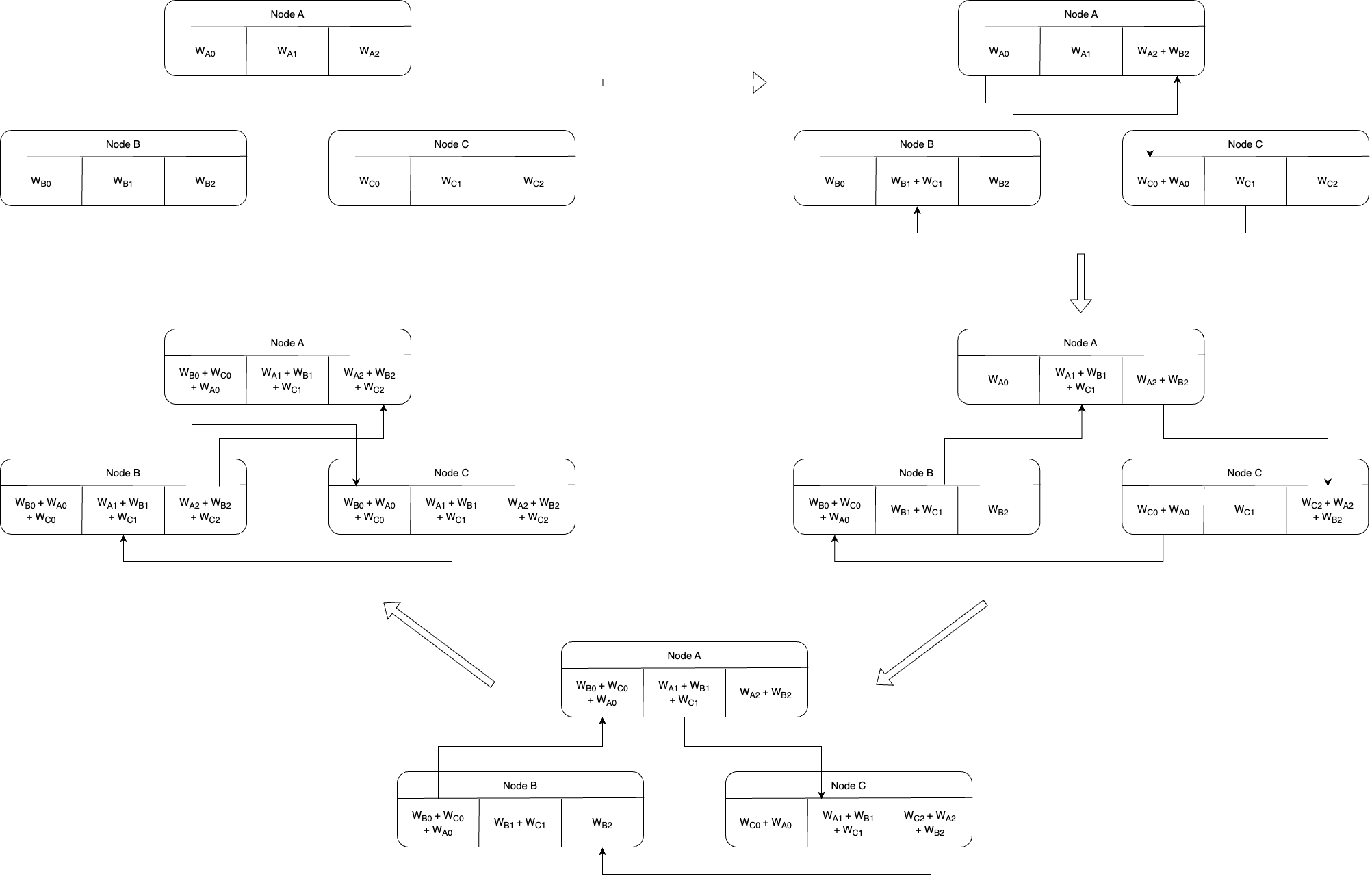
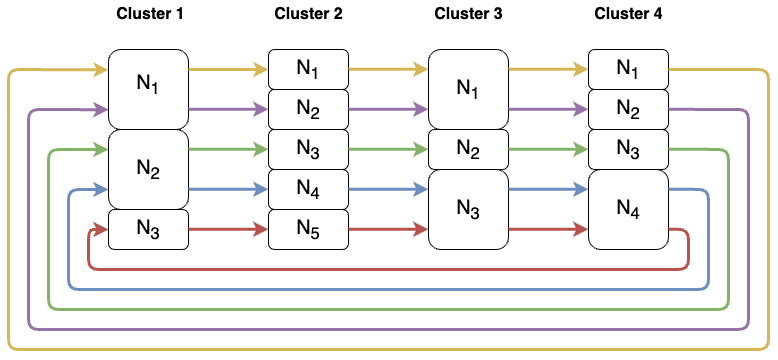
Fault Recovery & Dynamic Scaling
New peers can join ongoing training sessions at any time. Based on fault tolerance requirements, they either join existing clusters as backup nodes — mapped to the least reliable node with extra communication channels for seamless failover — or form entirely new clusters. This enables continuous training even as nodes drop in and out.
Under the Hood
Technical Deep Dive
The core algorithms and techniques that power Ravnest's distributed training.
Matchmaking & Cluster Formation
Compute nodes connect to an intermediary matchmaking server that profiles each node's hardware capabilities and network characteristics. Nodes are algorithmically grouped into clusters with similar data transfer rates and compute power, minimizing intra-cluster communication overhead and maximizing training throughput.
Zero-Bubble Model Parallelism
Within each cluster, the model is partitioned across nodes using model parallelism. A zero-bubble pipeline schedule feeds micro-batches through the pipeline stages asynchronously, ensuring that no node sits idle waiting for forward or backward passes from adjacent stages — eliminating the pipeline bubble problem.

Parallel Multi-Ring All-Reduce
Global parameter averaging is performed using a parallel multi-ring all-reduce algorithm that distributes communication load evenly across all nodes. This avoids the single-point bottleneck of a centralized parameter server and is triggered periodically to amortize communication cost.
Fault Tolerance & Dynamic Scaling
Designed for unreliable consumer-grade hardware, new peers can hot-join ongoing sessions. Newcomers either join existing clusters as backup nodes with extra communication channels mapped to the least reliable node, or bootstrap entirely new clusters — enabling continuous training as nodes drop in and out.
Gradient Compression & Adaptive Routing
To handle bandwidth constraints common in consumer internet connections, Ravnest compresses gradient updates before transmission. Adaptive routing algorithms select optimal communication paths between nodes, accounting for real-time network conditions and avoiding congested links.
Flexible Update Rule
A flexible parameter update rule allows slower devices to perform fewer local iterations before participating in global synchronization. This prevents stragglers from bottlenecking the entire training process while still incorporating their gradient contributions, enabling truly heterogeneous compute clusters.
Capabilities
Features
Built for real-world distributed training across diverse hardware and network conditions.
Asynchronous Training
No synchronization bottlenecks — nodes train asynchronously within clusters using zero-bubble pipeline parallelism.
Heterogeneous Devices
CPU and GPU systems participate in the same training session seamlessly, with workload adapted to each device's capabilities.
Data Compression
Integrated compression techniques reduce network overhead and improve training efficiency across bandwidth-constrained connections.
Auto Role Inference
A single common script for all provider roles — Ravnest automatically infers the node's role within the training topology.
LLM Model Splitting
Improved model splitting algorithms designed specifically for contemporary large language model architectures.
Custom Trainer
Extensible trainer API supporting non-conventional training flows and custom training loops for specialized workloads.
Auto Compute Detection
Automated detection of model compute requirements for optimal resource allocation across the cluster.
Comprehensive Docs
Extensive documentation on ReadTheDocs with feature updates, usage examples, and API reference.
Research
Experimental Results
Ravnest achieves convergence and validation accuracy competitive with centralized baselines, even when training is distributed across heterogeneous consumer devices.
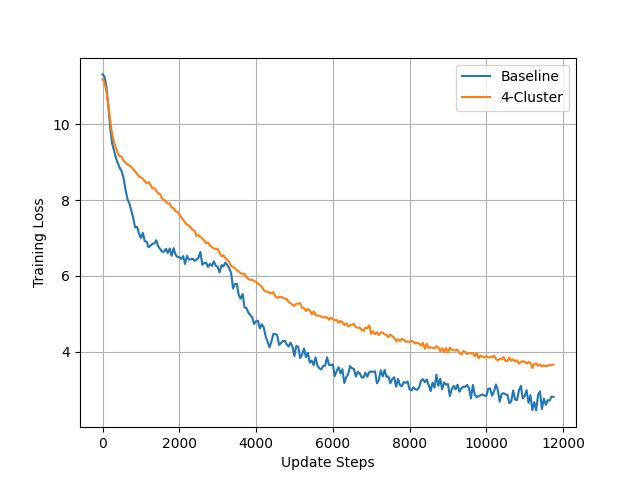
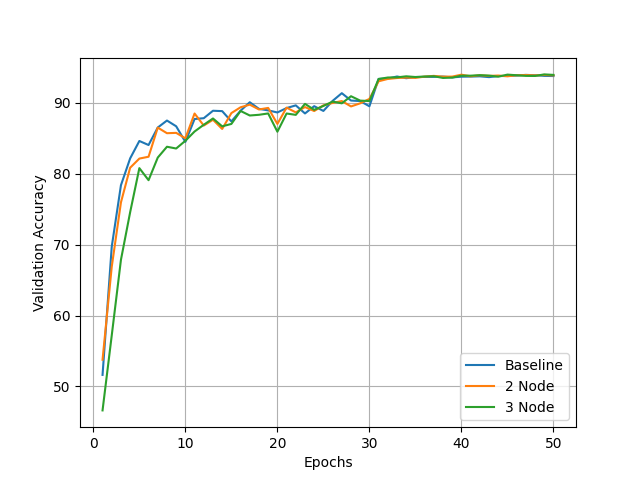
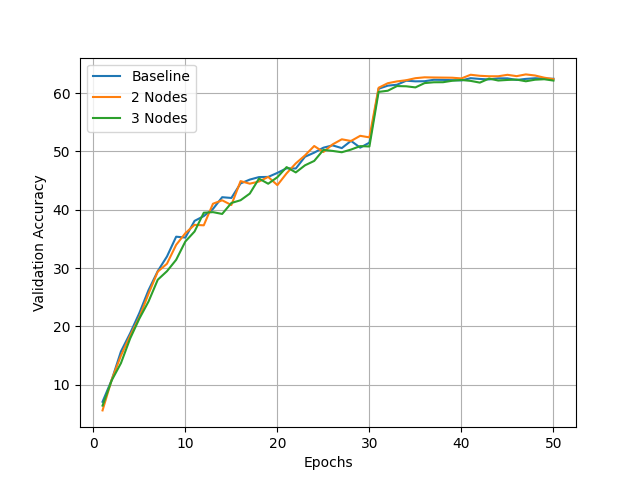
Compatibility
Supported Models
Benchmarked across vision models and small LLMs, with support for custom architectures.
Ravnest supports custom model architectures through its extensible trainer API.
Quick Start
Get Started
Install Ravnest and start distributed training in minutes.
Installation
Generate Submodels
Run cluster_formation.py to split your model into submodel files for each node.
Set Up Providers
Create provider instances for each node. Ravnest auto-infers roles within the cluster topology.
Launch Training
Execute each provider in separate terminals. Ravnest handles matchmaking, cluster formation, and distributed training automatically.